
순환신경망, RNN(Recurrent Neural Network)
🖇️ 순환신경망, RNN
기존의 인공신경망은 한 번에 하나의 입력을 독립적으로 처리하는 구조이기 때문에, 시간에 따른 데이터의 흐름을 처리하는 데에는 한계가 존재한다. 이러한 한계를 극복하기 위해 등장한 모델이 순환신경망 모델이며, 고정 길이의 입력이 아닌 임의의 길이를 가진 시퀀스를 처리할 수 있다. RNN은 시퀀스 모델 중 가장 대표적이고 기본적인 시퀀스 모델으로, 데이터의 순서를 고려하며, 과거의 정보를 현재의 계산에 재귀적(recurrent)으로 반영하는 구조를 가지고 있다. 즉, 이전의 '기억'을 활용하여 다음 작업을 수행할 수 있는 신경망이다.
RNN은 시계열 데이터나 자연어, 음성 데이터와 같이 순서가 중요한 문제를 잘 다루며, 자동 번역, Speech to Text와 같은 자연어 처리 작업에 매우 유용하다.
이 때, RNN이 순차 데이터를 다룰 수 있는 유일한 신경망은 아니다. 짧은 길이의 시퀀스는 일반적인 dense network가 처리할 수 있으며, 긴 길이의 시퀀스는 CNN에서 처리할 수도 있다.
🖇️ RNN의 작동 방식
RNN의 가장 큰 특징은 '순환 구조'를 가진다는 것이다. 일반적인 신경망은 '입력 → 은닉층 → 출력층'으로 한 방향으로 흐른다. 이에 반해, RNN은 자신의 이전 출력을 다음 입력 처리에 다시 사용한다. 이를 통해 시간에 따라 정보가 흐를 수 있는 구조를 가지고 있다.
RNN은 입력을 순서대로 받아들이고, 각 단계의 시점(time step) t에서 아래와 같은 연산을 수행한다.
hₜ = f(Wₓxₜ + Wₕhₜ₋₁ + b)
- xₜ : 현재 시점의 입력
- hₜ₋₁ : 이전 시점의 출력
- hₜ : 현재 시점의 출력
- Wₓ, Wₕ : 입력 xₜ와 출력 hₜ₋₁을 위한 가중치 벡터
- b : 편향
- f() : 활성화 함수 (ex. ReLU, tanh)
RNN은 매 시점마다 입력 xₜ와 이전 시점의 출력 hₜ₋₁을 함께 받아 새로운 출력 hₜ을 생성한다. 또한, 이전 단계에서는 입력 xₜ₋₁와 이전 시점의 출력 hₜ₋₂을 받아 새로운 출력 hₜ₋₁을 생성한다. 이와 같은 로직에 의해 결국 hₜ는 시간 t=0에서부터 모든 입력에 대한 정보를 포함한 함수가 된다. 따라서 hₜ가 RNN의 '기억' 역할을 수행하게 되며, 시퀀스 전체를 순차적으로 이해하게끔 한다.
RNN은 아래와 같은 신경망 chunk가 여러 개 복사된 사슬처럼 구성되어 있으며, 이 chunk를 셀(cell)이라고 한다. 타임 스텝에 걸쳐 이전의 모든 정보들을 기억하고 있는 일종의 메모리 역할을 하기 때문에 메모리 셀(memory cell)이라고 부르기도 한다.

셀은 다음 상태(state, 현재 시점의 출력, hₜ)를 계산하기 위해 이전 상태(state, 이전 시점의 출력, hₜ₋₁)을 사용한다.


🖇️ RNN의 예시
"hello"라는 한 문자열에 대하여 학습하는 시퀀스가 있다고 가정해보자. 이 때 우리는 V∈{"h","e","l","o"}라고 하는 어휘를 가지게 된다. 우리의 목표는 RNN이 훈련 데이터인 문자열에서 시퀀스의 다음 문자를 예측하도록 학습하는 것이다.

위의 그림과 같이, 한 번에 한 문자씩 RNN에 입력할 것이다. ("h", "e", "l", "l") 각 문자는 one-hot encoding을 통해 one-hot 벡터로 인코딩되며, 어휘의 각 고유한 문자에 대하여 벡터의 고유한 비트 하나만 켜진다.
그런 다음 RNN의 반복적인 구조를 모든 타임 스텝에서 사용한다. 이 때 초기의 벡터 h는 0으로 구성된 사이즈 3의 벡터로 시작한다고 가정한다. 반복 구조를 모두 마친 후, 3차원의 표현(representation)을 얻게 된다. 이는 이전 시점까지 등장했던 모든 특징을 포함하고 있는 정보로 이해할 수 있다.

모든 타임 스텝에서 이 반복을 적용하기 때문에 모든 타임 스텝에서 시퀀스의 다음 문자가 무엇인지 예측할 수 있다. 우리가 가지고 있는 어휘 V에는 네 개의 문자가 있기 때문에, 모든 타임 스텝에서는 4차원의 logits 벡터를 예측할 것이다. 예시에서 타임 스텝에 따라 예측하는 logits은 Fig 3에서의 output layer의 값들이라고 이해하면 된다. (* logits이란, softmax 함수가 적용되기 전의 출력값을 의미한다. 일반적으로 신경망의 마지막 레이어의 출력은 softmax를 적용하여 확률로 바꾸는데, 그 이전 값이 logits이다.)
첫 번째 타임 스텝 이후, RNN이 문자열 "h" 이후 문자를 예측하기 위해 다음 문자에 대한 logits을 계산한 것은 Fig 6과 같다. 4.1의 점수로 "o"가 다음 순서로 올 것이라고 RNN은 예측하고 있지만 실제로는 "e"가 오기 때문에 틀린 예측이다. RNN이 다음 문자를 잘못 예측했기 때문에 실제 정답과 오답을 기반으로 softmax 분류기를 이용해 손실(loss)를 계산한 뒤, 역전파를 통해 모델의 가중치를 업데이트한다. 이를 통해 모든 가중치 행렬의 기울기를 계산하고, 정답에 가까운 예측이 나오도록 업데이트 하는 과정을 거친다. 이 과정이 바로 딥러닝에서 말하는 "학습"을 의미한다.
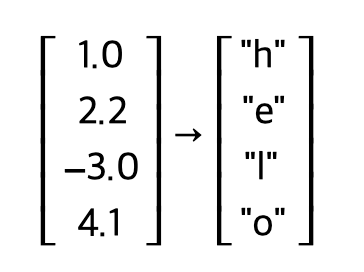
🖇️ 출처
Understanding LSTM Networks -- colah's blog
Posted on August 27, 2015 <!-- by colah --> Humans don’t start their thinking from scratch every second. As you read this essay, you understand each word based on your understanding of previous words. You don’t throw everything away and start thinking
colah.github.io
CS231n Convolutional Neural Networks for Visual Recognition
Table of Contents: Introduction to RNN In this lecture note, we’re going to be talking about the Recurrent Neural Networks (RNNs). One great thing about the RNNs is that they offer a lot of flexibility on how we wire up the neural network architecture. N
cs231n.github.io
'AI > 핸즈온 머신러닝' 카테고리의 다른 글
| Latent Space의 의미와 활용 (0) | 2025.04.14 |
|---|





