
[논문 Review] Playing Atari with Deep Reinforcement Learning (NIPS 2013)
* 여름 연구실 인턴 정기 미팅에서 논문 리뷰한 것을 정리한 게시글입니다.
* 발표 자료는 직접 제작했으며, 사진이나 자료의 출처는 페이지에 바로 표시해두었습니다.
* 2021. 07. 07(수) 발표

먼저 ICML, NIPS, AAAI 등의 학회 사이트에서 여러 논문들을 살펴봤을 때 공부해볼 수 있는 주제가 너무 광범위하다는 생각을 했다. 그래서 큰 분야를 먼저 정해놓고 세부적으로 접근해보자 라고 생각했다. 그리하여 머신러닝의 세가지 분야 중에서 Reinforcement Learning, 강화학습을 주제로 하여 세부적으로 논문을 찾아보게 되었다.
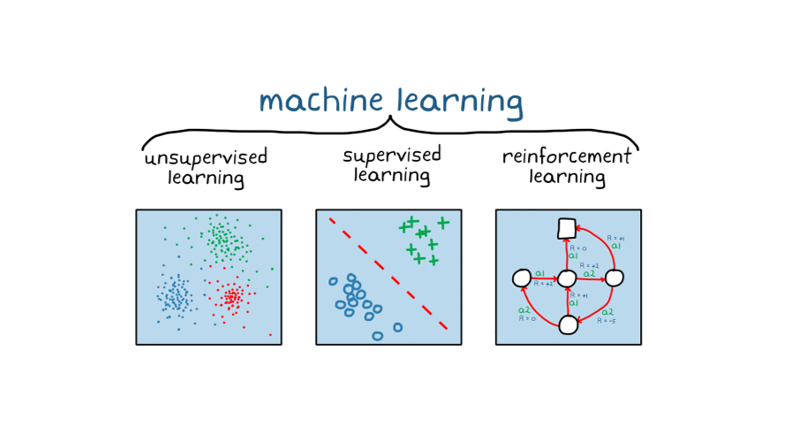
강화학습은 지도, 비지도학습과는 달리 변화하는 환경으로부터 직접 보상을 받으며 학습한다는 점에서 ‘스스로 학습’한다 라는 특징이 있는데 특히 대표적인 예시로는 몇 년 전의 알파고가 있다. 기계가 전적으로 스스로 학습한다는 점이 인상적이라서 더 알아보고 싶어 이번주 주제로 선정하게 되었다.
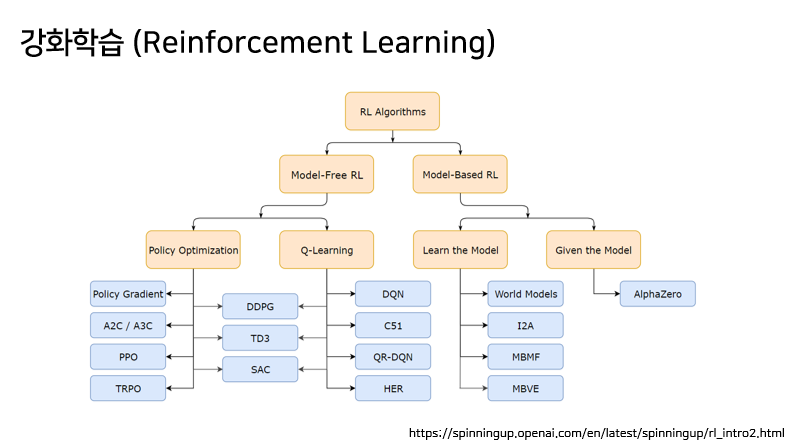
강화학습은 크게 위와 같이 분야가 나누어볼 수 있다. 그 중에서도 크게 Model-Free와 Model-Based 2가지로 나뉘는데, 그 중에서도 강화학습의 기초에 대해 배우려면 DQN을 먼저 공부하는 것이 좋다고 하여 이를 먼저 공부하게 되었다.

이번에 공부하기 위해 선정하게 된 논문이 Playing Atrai with Deep reinforcement learning이다. 이 논문은 2016년 알파고를 개발한 구글의 딥마인드 팀에서 NIPS 2013년에 발표한 논문이며, 여기서 내용을 좀 더 보강하여 2015년에 네이처에 기고했다고 한다. 이 논문은 최초로 강화학습에 딥러닝의 방법론을 결합하여 제시한 논문으로서 의의가 있다.

먼저 논문은 위와 같이 요약해볼 수 있다. 이 논문에선 음성, 이미지와 같은 high-dimensional sensory input으로부터 강화학습을 통해 control policy를 성공적으로 학습시킨 최초의 딥러닝 모델이다.
이 모델은 CNN을 기반으로 해서 Q-러닝을 변형시킨 형태의 모델이다. 또 이 모델을 가지고 직접 Atari 게임을 여러 차례 돌려봤을 때 모델의 조정이나 하이퍼 파라미터의 조정 없이 게임에서 성공적인 결과를 이끌어냄으로써 딥러닝을 적용한 강화학습이 잘 된 것을 보이고 있다.

이 모델을 구현하게 된 배경을 크게 강화학습과 딥러닝, 2가지 측면으로 나누어 설명하겠다.
우선 강화학습의 경우, 이 논문이 발표되기 전에는 음성이나 이미지와 같은 고차원의 sensory input에서는 에이전트를 학습시키기 어려웠다고 한다. 또한, 당시의 연구들은 사람이 직접 조정한 hand-craft feature에 많이 의존적이었으며, 이 때문에 data quality도 많은 영향을 받았다고 한다.

동시에, 딥러닝은 발전을 거듭하는 중이었고, 당시 CNN 구조 모델인 AlexNet이 등장했다. 이를 통해 raw data로부터 High-level feature를 추출할 수 있게 되면서 이미지나 음성을 인식하는 기술이 발전하게 되었고, 다양한 CNN, RNN, Multi-Layer 퍼셉트론 등의 기법들이 탄생했다.
이러한 두 가지 배경에서, 딥마인드 팀에서는 "과연 딥러닝 기술을 강화학습에 적용해도 효과가 있을것인가?" 라는 질문을 던지게 된다.

그런데 강화학습과 딥러닝은 서로 다른 특성 때문에 바로 결합하기가 어렵다.
크게 세가지 특징 때문인데, 우선 딥러닝은 대량으로 Hand-labeled된 데이터가 필요하지만 대부분의 강화학습에는 그러한 데이터가 부재하다. 또한, 딥러닝은 서로 독립적인 데이터로부터 학습하지만 강화학습은 높은 상관관계를 가진 데이터들이 sequence로 학습하기 때문에 비독립적이다. 마지막으로 강화학습에서는 새로운 학습을 할 때마다 Data Distribution이 변화한다고 가정하는 반면, 딥러닝에서는 데이터 분포가 고정되어 있다고 가정한다.
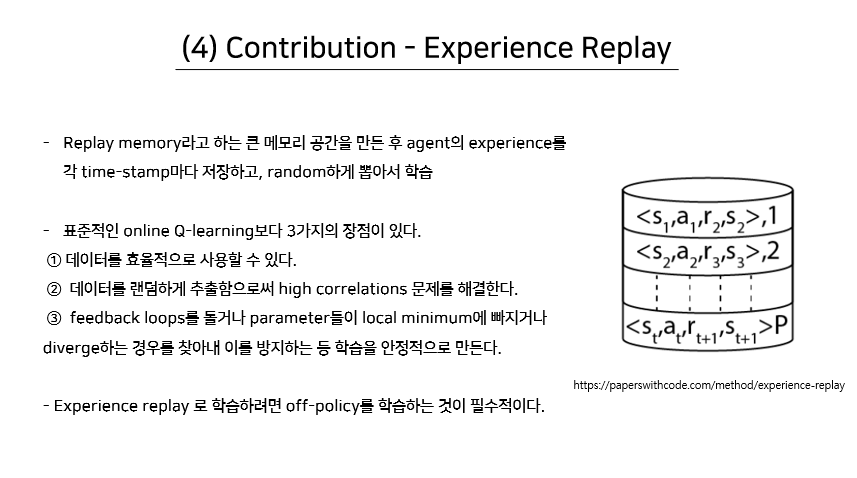
딥마인드에서는 위와 같은 문제점들을 극복하기 위해 크게 2가지의 방법을 제시한다.
우선 강화학습의 데이터가 High-correlation의 관계를 가진다는 점을 극복하기 위해 Experience replay를 제안한다.
Experience replay란, Replay memory라고 하는 큰 메모리를 만든 후에 agent의 experience를 각 타임스탬프마다 저장하고, 랜덤하게 뽑아서 학습하는 방법을 말한다. 이를 통해 데이터의 높은 상관관계를 극복하고, 데이터를 효율적으로 사용할 수 있으며, 학습을 안정적으로 만드는 데에도 도움을 준다. 이 때, 참고할 점은 Behavior policy와 Learning policy가 다르기 때문에 Q-러닝의 choice를 원활하게 하는 off-policy를 학습하는 것이 필수라고 한다.

두번째로 딥마인드는 CNN 기반의 모델을 제안한다.
4개 화면의 프레임이 raw pixel로서 input 데이터로 사용되며, output은 input state에 대한 개별 action의 예측한 Q-value에 해당한다. 이 모델을 통해 별도의 전처리를 통해 특징을 추출하는 것보다 좋은 결과를 얻을 수 있게 된다.
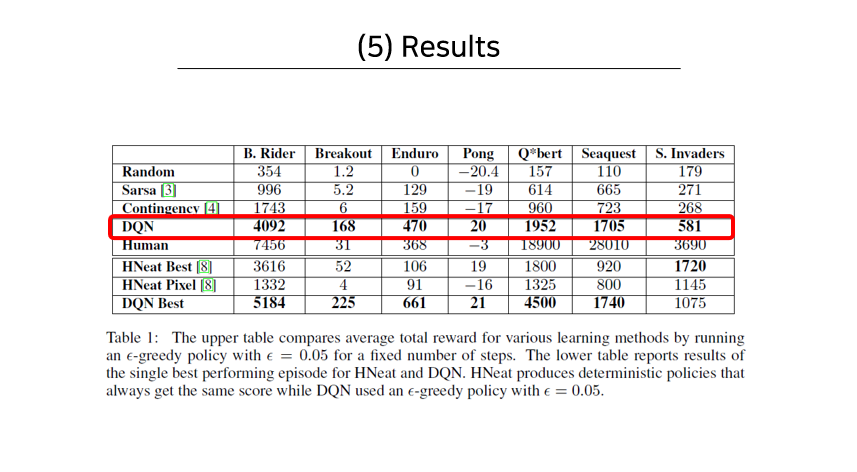
위의 모델을 가지고 딥마인드 팀에서 실험한 결과를 보여주는 표다. 빨간색 박스로 표시한 부분이 딥마인드에서 제시한 DQN 모델에 대한 결과이며, 다른 모델을 사용하거나 사람이 직접 했을 때보다 상당히 높은 값을 얻은 것을 볼 수 있다.

또한 논문에서는 보다 세부적인 분석 결과표도 제시한다.
위의 그래프 두개는 rewards의 변화를 기준으로 하고 있으며, 아래의 그래프들은 Q-Value 값을 기준으로 하고 있다. Reward 기준의 그래프에서는 마치 학습이 안되는 것처럼 보일 수도 있지만, Q-Value 값이 일정한 값으로 수렴하는 것을 보임으로써 학습이 잘 진행되고 있는 것을 볼 수 있다.
* Q-Value = 에이전트가 어떤 상황에서 어떠한 정책에 따른 액션을 취했을 때 반환되는 값의 기대값

또한 게임 화면을 통해서도 실험 결과를 확인해볼 수 있다.
아래의 A 화면은 노란색 아군이 적군을 대치했을 때, B 화면은 아군이 날린 대포를 적군이 맞기 직전일 때, C 화면은 아군이 날린 대포를 맞고 적군이 사라졌을 때의 화면이다. 위의 Q-Value 그래프를 보면 대포를 적군이 맞기 직전인 B에서 Value값이 제일 높고 그 이후에는 급격하게 떨어지는 것을 볼 수 있다.

논문에서는 강화학습을 위한 새로운 딥러닝 모델을 최초로 소개했다. 특히 사람이 직접 play하는 것처럼 스스로 학습하는 네트워크를 만들고자 했으며, 이 네트워크는 아키텍쳐나 하이퍼 파라미터 조정 없이 7개의 게임에서 모두 최고의 성능을 발휘함으로써 성공한 결과를 보이고 있다.

이 논문 이후 Human-level control through deep reinforcement learning이라는 논문도 추가로 읽어보고 싶었는데 시간이 부족해서 아직 공부해보지 못했다. 이 논문 또한 강화학습의 DQN을 다룬 것으로 이번 논문보다 좀 더 구조가 복잡하다는 특징을 가지고 있다.
또 강화학습 자체에 관심이 생겼는데, 「Reinforcement Learning: An Introduction」라는 도서가 강화학습에서 바이블이라고 불린다고 한다. 이 도서에 대해서도 공부해보려고 한다.









