
[논문 Review] Generative Adversarial Networks (NIPS 2014)
* 여름 연구실 인턴 정기 미팅에서 논문 리뷰한 것을 정리한 게시글입니다.
* 발표 자료는 직접 제작했으며, 사진이나 자료의 출처는 페이지에 바로 표시해두었습니다.
* 2021. 07. 14(수) 발표

AI의 권위자 중 한 분이신 얀 르쿤(Yann LeCun)은 GAN을 두고 머신러닝 분야에서 최근 10년 중 가장 흥미로운 아이디어라고 언급했다. 과연 어떤 아이디어길래 하루가 멀다하고 새로운 아이디어가 쏟아져나오는 ML 분야에서 가장 흥미롭다고 극찬한 것인지 궁금해서 이번주 공부 주제로 GAN을 선정하게 되었다.

최초로 GAN 모델을 제안한 논문은 Generative Adversarial Nets라는 논문으로, NIPS에서 2014년에 발표되었다.

우선 GAN 모델의 풀 네임인 Generative Adversarial Networks를 두고 한 단어씩 살펴보면서 어떤 모델인지 개략적으로 유추해보자.
먼저 Generative라는 단어는 "무언가를 생성한다" 라는 의미다. 즉, GAN 모델은 뉴럴 네트워크를 이용해서 무언가를 생성하는 모델이라는 것을 짐작해볼 수 있다. GAN은 이름에서 볼 수 있듯, 흔하게는 이미지를 생성하는 것에서부터 음성, 문자에 이르기까지 다양한 분야에 적용되는 생성모델이다.

GAN에서는 수많은 모델들이 파생되었는데, 위는 GAN에서 파생된 여러 개의 모델 중 하나이자 구글에서 발표한 BEGAN 모델에 의해 생성된 사람 얼굴 이미지들이다. 이 사진들은 모두 실존하는 인물이 아니라 BEGAN 모델을 사용해서 생성해낸 허구의 인물들인데, 마치 어딘가 있을법한 사람들의 모습처럼 정교하게 보인다.
지난 학기 수업을 통해 배웠던 CNN 모델이 이미지를 분류하고 구별하는 모델이었다면, GAN은 이미지를 만들어내는 모델이다.

다음으로 Adversarial이라는 단어는 사전적으로는 "대립하는, 적대하는" 이라는 뜻을 갖고 있다. 대립한다는 건 상대방이 필요하다는 의미도 갖고 있다. 따라서 이 단어를 통해 GAN 모델에서는 크게 대립하는 두개의 모델로 나누어져 있겠구나 라고 짐작해볼 수 있다.

실제로 GAN에서는 생성모델 Generator G와 판별모델 Dicriminator D 이라는 두 개의 모델이 존재한다. GAN에서는 이 두개의 모델을 적대적으로 경쟁시키면서 발전시키는 구조를 가지고 있다.
GAN의 모델을 설명할 때 대표적인 예시로 위조지폐범과 경찰의 관계를 들어서 설명하곤 한다. 위조지폐범은 최대한 진짜 같은 위조지폐를 만들어서 경찰을 속이기 위해 노력하고, 경찰은 진짜 지폐와 위조범이 만든 위조지폐를 완벽하게 구별하고 위조지폐범을 검거하는 것을 목표로 한다.
이렇게 위조지폐범은 계속해서 위조지폐를 생성하고, 경찰은 진짜 지폐를 찾기 위해 노력하는 과정에서 서로 적대적으로 경쟁하면서 학습하고, 이 과정에서 두 그룹이 서로를 속이고 구별하는 능력이 발전하게 된다. 이것이 바로 GAN의 전체적인 컨셉이라고 볼 수 있다.

다시 GAN의 Full name으로 돌아와서 보자면, GAN의 핵심 컨셉을 다음과 같이 이해해볼 수 있다.
각각의 역할을 가지고 있는 생성모델과 판별모델이 서로 적대적인 학습을 하면서 ‘진짜 같은 가짜’를 생성해내는 능력을 키우는 네트워크 모델.

GAN은 머신러닝 중에서도 Unsupervised 학습방식에 속한다. Unsupervised 학습방식은 input data에 대한 label, 즉 정답을 가지고 있지 않는다. 따라서 주어진 입력 데이터에 의존해서 군집을 찾는 학습방식이다.

예를 들어 앞에서 예시를 들었던 BEGAN 모델의 얼굴 데이터를 가지고 설명을 하겠다.
Unsupervised 학습 방식에서는 우리가 원하는 도메인, 여기서는 사람 얼굴에 해당하는 데이터나 사진들을 입력값으로 넣게 된다. 이 때 사진 각각에 대해 A사람이다 혹은 B사람이다 라는 라벨은 없기 때문에 GAN의 생성자는 사람 얼굴이라는 도메인으로부터 사람의 얼굴이라는 특징 패턴을 학습하게 되고, 최종적으로 매핑으로 이어지는 비지도 학습을 진행한다. 학습 이후에는 위의 예시처럼 실제로 있을법한 사림 얼굴 이미지를 생성할 수 있게 된다.

GAN 모델에 사용되는 식을 설명하기 위해 경찰과 위조지폐범의 예시를 들어서 다시 보겠다.
위조지폐범 즉, Generator 모델은 점점 더 실제 이미지와 닮은 샘플을 생성하기 위해 노력할 것이고, 경찰 즉, Discriminator는 샘플을 점점 더 잘 구별할 수 있도록 노력할 것이다. 이를 다른 표현으로 다시 말해보자면, Generator는 Discriminator가 실수할 확률을 높이기 위해 노력할 것이고, Discriminator는 자신이 실수할 확률을 낮추기 위해 노력할 것이다.
이를 수식으로 정리하게 되면, 우리가 하고자 하는 것은 맨 하단에 있는 빨간 네모 속의 가치함수 V(D, G)에 대한 최소최대문제, 즉 minimax problem을 해결하는 것과 같아진다.
* 가치함수 = 현재 상태의 정책을 따라갔을 때 최종적으로 받을 것이라 예상되는 보상의 총합.
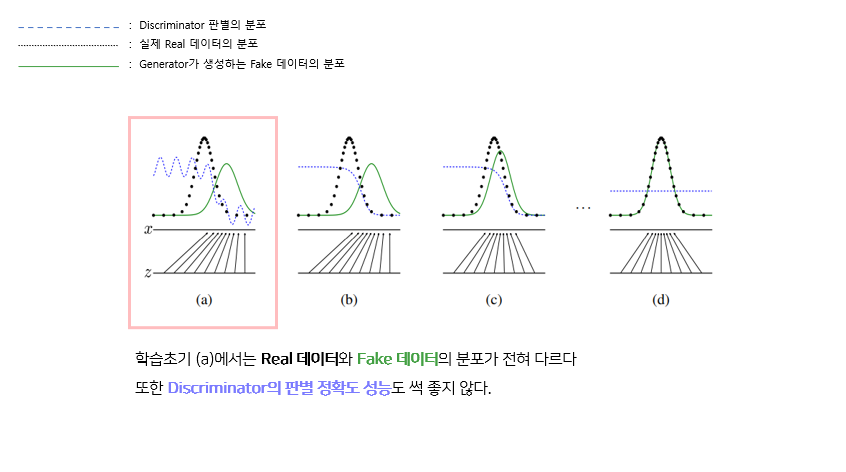
이 논문에서는 GAN의 학습과정을 위와 같은 그래프로 설명하고 있다.
파란색 점선은 Discriminatior 즉, 경찰이 해당 데이터를 보고 진짜인지 가짜인지 판별하는 것의 확률을 나타낸다. 검은색 점선은 실제 데이터의 분포를 나타낸다. 그리고 초록색 실선은 Generator 위조지폐범이 생성하는 가짜 데이터의 분포를 나타낸다.
학습초기의 모습을 보면, Real 데이터와 Fake 데이터는 전혀 다른 데이터의 분포를 보이고 있다. 또한 Discriminator의 경우 판별이 들쭉날쭉하여 정확도 성능이 썩 좋지 않은 것을 볼 수 있다.
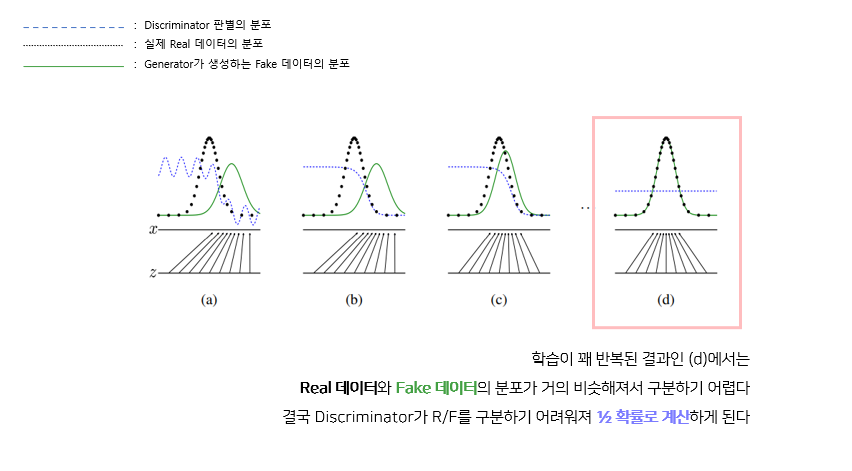
이번에는 학습이 꽤 진행된 이후의 그래프를 보겠다. Real과 Fake 데이터의 분포가 거의 비슷해져서 구분하기 어려워진 것을 볼 수 있다.
그에 따라서 Discriminator는 real과 fake를 구분하기 어려워지기 때문에 판별 확률을 ½로 계산하게 된다. 이 과정으로 진짜와 가짜 이미지를 구별할 수 없을만한 데이터를 G가 생성해내고, 이것이 바로 GAN의 최종 결과가 된다.

여기서부터는 논문에서 보이는 실험 결과들이다. 연구진들은 MNIST, TFD, CIFAR-10의 데이터셋을 두고 GAN 학습을 진행했다. 여기서 생성된 샘플들은 기존 방식으로 만든 샘플보다 좋다고 주장하기 어렵다고 밝히지만, 동시에 논문에서 비교한 다른 모델들에 견주어봤을 때 GAN의 잠재력이 크다는 점을 어필하고 있다.

실제로 GAN 모델에는 위와 같은 많은 장점들이 존재한다.

하지만 초창기의 GAN 모델들은 안정적으로 학습되기 어려웠기 때문에 좋은 성능을 얻기 어려웠고, 결과물에 대한 객관적인 평가가 어려웠다는 큰 단점이 있었다. 그렇기 때문에 초기에는 GAN을 응용하는데에 많은 어려움이 있었다.

이러한 GAN의 한계들을 극복하기 위해 DCGAN이라는 모델이 등장한다. 이 모델은 CNN모델에 GAN을 접목시킨 모델로, 이 모델이 나온 이후 GAN 결과들이 매우 급격하게 발전하기 시작했다고 한다. 또한 이후에 발표되는 GAN의 파생 논문들이 대부분 DCGAN의 구조에 베이스를 두고 있을만큼 큰 영향을 끼쳤다.
이 논문은 다음 게시글에서 다뤄보겠다.









